
Examining Google’s SGE Patent and Making Predictions For The Future
Where might this rollercoaster take us?

SGE is the most radical shift in the Google search experience in a long time, quite possibly ever. Content creators are frustrated (rightly-so) with how Google is taking liberties with their content, especially after being left in the dark during the Helpful Content Update.
Let’s open the hood here and try to better understand how their AI Overview system works, how it might be connected to other parts of their eco-system, and what the future might look like if Google keeps going in this direction.
Google filed for the patent in 2023, not earlier - potentially indicating that they were caught off guard by the success of ChatGPT. The patent was written by several Google research scientists and engineering team members from the search team. Many of them have participated in other Google patents, and are, obviously, intricately familiar with how all of the Google systems are intertwined.
Under the hood of Google’s AI Overviews (f.k.a. SGE)
The patent itself is quite long (30 pages when printed!) so i’ll spare you all of the tech jargon and give you a layman’s overview of how it works…

Google starts with its typical query ingestion and understanding process. Once has determined the context of the query, things begin to rapidly diverge from the standard way Google determines search rank.
Using the query, and other information it feels is relevant, Google retrieves several SRDs or Search Ranking Documents, which are pages that could potentially rank for a given query. These are returned and ranked based on several factors - some of the usual suspects like trustworthiness, authorship, inbound links, etc. They also consider how “summarizable” a given article is based on several internal factors not listed in the patent.
This is likely why you don’t always only see top-ranking documents as sources in SGE.
From there Google selects which of its LLMs it might want to use based on which documents it selects. We know Google has several different models to choose from when considering how to generate a response. They can use as many as they deem necessary at this step.
Once snippet responses are generated, they are recombined using a separate engine that brings all of the responses together in a sensible way. Think of this like taking pieces from different Lego sets and building a new thing.
At that point Google begins checking the response for accuracy and measuring the confidence level. This is done one sentence at a time using the cosine similarity of the original source snippet to the Google-generated snippet.
The patent specifically states that higher confidence responses have a lower chance of having their sources cited. To me, this feels similar to what they do with their Instant Answers featured snippet.
Once each snippet in a generated response has been verified with at least one SRD, the complete response is sent back to the client device for rendering.
Important to note is that each generated snippet has “meta-data” which includes what SRDs it was generated from, as well as what SRDs it was verified against. We only get to see a small portion of that on the front end in the format of clickable links in a sliding panel under the generated result.
How is information verified and cited according to the patent?
Here is the portion of the patent that describes their process for verifying and citing information:

Once an answer is generated, Google begins the process of verifying the individual sentences within the response one at a time.
They select one of the possible search ranking documents associated with generating the answer or ranking organically for a given query. They do this by extracting a portion of the SRD and comparing the content embedding to the content embedding of the LLM-generated response. The passage is then verified if the distance between the two embeddings is less than a specific threshold.
Once a section is verified, the associated url that was used to validate the portion and the verified AI output are “linkified” or connected together. In the example below, the LLM-generated response about “Bad mood may cause…” was verified in the linked Travel China Guide article listed below.

Once that source is clicked, you are taken directly to that portion of the article with the content used to validate the LLM-generated response, highlighted. If one wished (cough Google cough), incorrect answers could be debugged in this way to determine patterns and improve the accuracy of the generated responses.

What do the different colored backgrounds of AI Overviews mean?
SGE was the first real introduction of color to the Google SERP page - but what do the different colors mean?
Colors seem to illustrate Google’s level of confidence in the synthesized answer that its system provides. They do reference this in the patent but only using general examples.
Here is how the use of color is described within the patent:
For example, a portion with a high confidence measure can be annotated in a first color (e.g., green), a portion with a medium confidence measure can be annotated in a second color (e.g., orange), and a portion with a low confidence measure can be annotated in a third color (e.g., red).
How should we interpret this? Well in my 24 hours of testing post-Google I/O, using a logged-in, but non-Search Labs enabled account, I was able to get 5 different color variations of the AI Overview panel.

This feels like an extrapolated version of what Gemini does in its chat interface by highlighting parts of the text it has found content similar to on the web in green, and highlighting content it has found various answers for in orange.
With that, we can possibly deduce that the scale likely goes from Green → Orange in terms of how confident Google is in its generated response.
In the example above, the answer to when is the Lunar New Year, or where do puffins live, do have more fixed answers than something like how to make a latte, or who is the richest person in the world.
The patent does describe what is called “confidence annotations,” perhaps color is how Google chose to implement this. Either way, it would be good for them to communicate this as most of the medical queries I found with AI Overviews…were red.
Why do we see things that don’t make sense in certain responses?
Besides the fact that LLMs have hallucinations, Google’s process for validating the accuracy of a generated passage using cosine similarity sits on a bit of shaky ground.
We can assume that Google is just as good, if not better, than Netflix at building and comparing embeddings, but this study does prove there is at least some wiggle room when using this method to compare snippets of text.
Especially when not manually reviewed, and trained by a human, like their search results have been using quality raters.
Additionally, source documents selected for summarization are not selected in the same way as Google’s organic algorithm works. The patent specifically calls this out by stating that Google may use one or more ranking systems to determine which documents it uses as sources for LLM summaries. See below:
For example, the system can select, for inclusion in the set, a subset of query-responsive SRDs that the system and/or a separate search system have identified as responsive to the query. For instance, the system can select the top N (e.g., 2, 3, or other quantity) query-responsive SRDs as determined by a search system or can select up to N query-responsive SRDs that have feature(s), as determined by the system, that satisfy one or more criteria.
Since this is all being done algorithmically, they can select a source document that meets the criteria of the selection engine but is factually inaccurate.
That is the case in the below example suggesting that it is ok to drive while drunk in the country Barbados shared by MartinMacDonald on X:
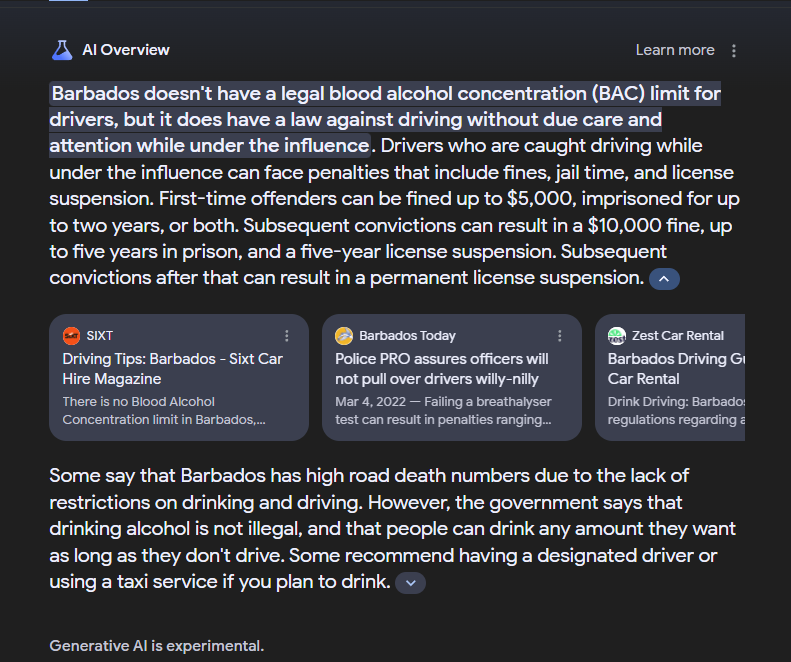
In this case, and in a few others, it would seem that the SRD selection process needs to be refined, or that the validation engine needs to seek out and confirm that a generated passage is similar to passages found on multiple high-authority websites before validating the response in the response confidence engine.
Unused parts of the patent and how this experience might evolve
Aside from just making this product work correctly so they don’t destroy the goodwill they have built up over 15 years (maybe they already have) - the patent outlines a few additional behaviors not currently seen in the production version of AI Overviews.
Real-time answer refinement
The patent also describes a way for this AI Overview panel to adapt based on user behavior. This behavior might include clicking one of the sources, toggling one of the listed source panels, or perhaps even click/hover behavior like they use for standard organic ranking.
In practice this seems more like how a pack of PAA questions work, in that when you toggle one open, you’re often presented with several more related questions below the original 4.
This makes sense as one of the inventors of the SGE patent was also the search team engineer behind the implementation of People Also Ask several years ago.
Integration of user profile data
The true moat here for Google is to leverage its understanding about you as a human and then generate an answer based on your past searches, as it understands you have a different potential level of understanding about a topic.
The patent does indeed discuss this:
it can be determined, based on a profile associated with the query (e.g., a device profile of the client device via which the query was submitted and/or a user profile of the submitter), whether the submitter of the query is already familiar with certain content that is responsive to the query. If so, additional content, that reflects familiarity of the user with the certain content, can be processed using the LLM in generating the NL based summary.
While this likely needs more consideration due to all of the privacy issues it brings up - it give Google a big leg up over its rivals and really shows the direction this could all be going in a few years.
Imagine if you were a dog owner researching breeds, vets, or pet accessories for hard chewers. Let’s say at some point you also searched for a brush to comb through a german shepherd’s coarse hair. 6 months later you are searching for something like “Why is my dog limping?”
The magical part would be if Google can remember that not only do you have a German Shepard, but also knows they are more likely to have hip dysplasia. Google then generates an AI response stating that it is common for shepards to have hip dysplasia and suggests you visit your local vet with the specific phone number you’ve searched for before.
Magic.
This is also likely why it currently requires a logged-in profile to display a LLM-generated overview.
Wrapping up
Who knows where this is going but it is certainly a very exciting time to be alive.
We cannot go back to how it was before, the cat is out of the bag. Whether we like it or not, information is beginning to become a commodity, and standing out is going to be increasingly hard if you are in the content business.
The SEO community would be wise to begin diversifying and researching new ways to think about their craft.
As ancient Greek philosopher Heraclitus said - the only constant, is change.
If anyone else has spent time digging into this, let me know in the comments!